

Getting Started with Data Engineering: A Step-by-Step Guide


Are you interested in becoming a data engineer but don't know where to start? In this post, I'll walk you through the basics of data engineering using a simple project that involves fetching data from GitHub and visualizing it through Looker.
Steps:-
Here's what you need to do:
Select a programming language: Data engineering requires you to be proficient in at least one programming language. Python is a popular choice because it has a rich set of libraries that can be used for data manipulation, transformation, and analysis.
Choose a cloud provider: Several cloud providers offer data engineering services such as AWS, GCP, and Azure. For this project, we'll be using GCP because it provides an easy-to-use service called BigQuery for storing and analyzing large datasets.
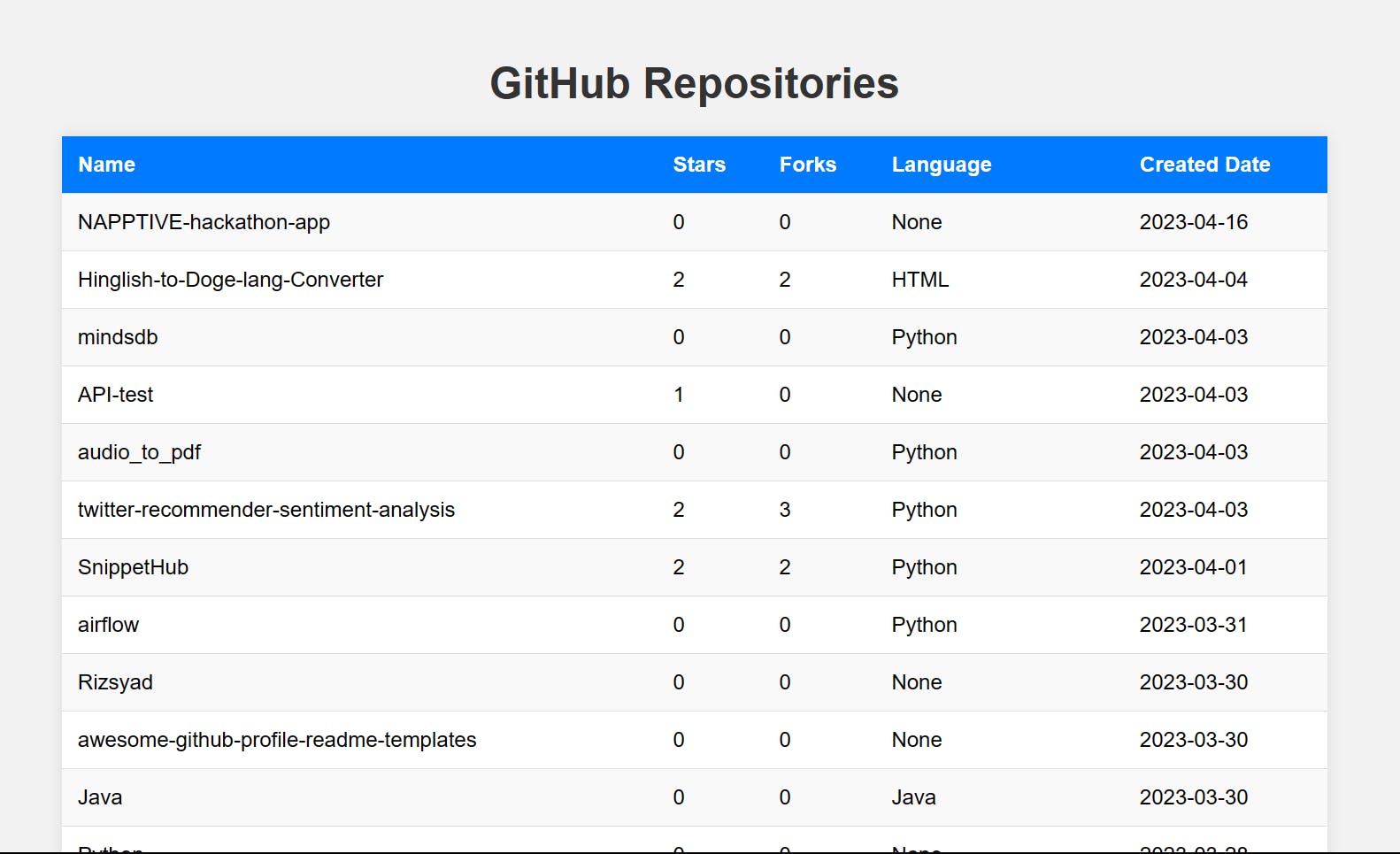
ETL: ETL stands for extract, transform, and load. This is the process of taking data from one source, transforming it to meet your requirements, and loading it into a destination. In our project, we'll be using an API provided by GitHub to extract data about the top 200 repositories with the highest stars.
Load data into BigQuery: Once we have the data, we need to load it into BigQuery so that we can analyze it. We'll be using the BigQuery Python client library to do this.
Visualize the data: Finally, we'll be using Looker to visualize the data. Looker is a business intelligence tool that allows you to create interactive dashboards and reports.
But wait, there's more! To automate this process and make it repeatable, you'll need an orchestration tool like Apache Airflow or Apache NiFi to schedule and execute your data pipeline.
If you're interested in seeing the project in action, you can check it out here: https://github.com/rohan472000/Github-repo-extraction-GCP
Results
Data engineering can seem overwhelming at first, but with a little bit of practice and patience, you'll be able to master it in no time. Good luck!