

Table of contents
Introduction
In this project, I'm going to show you my web scrapping project which is of course very small but will give you an insight into web scrapping.
I've done web scrapping over a FlipKart item (hp Pavillion laptop), you can choose your own, using some libraries and making a function for it.
Codes
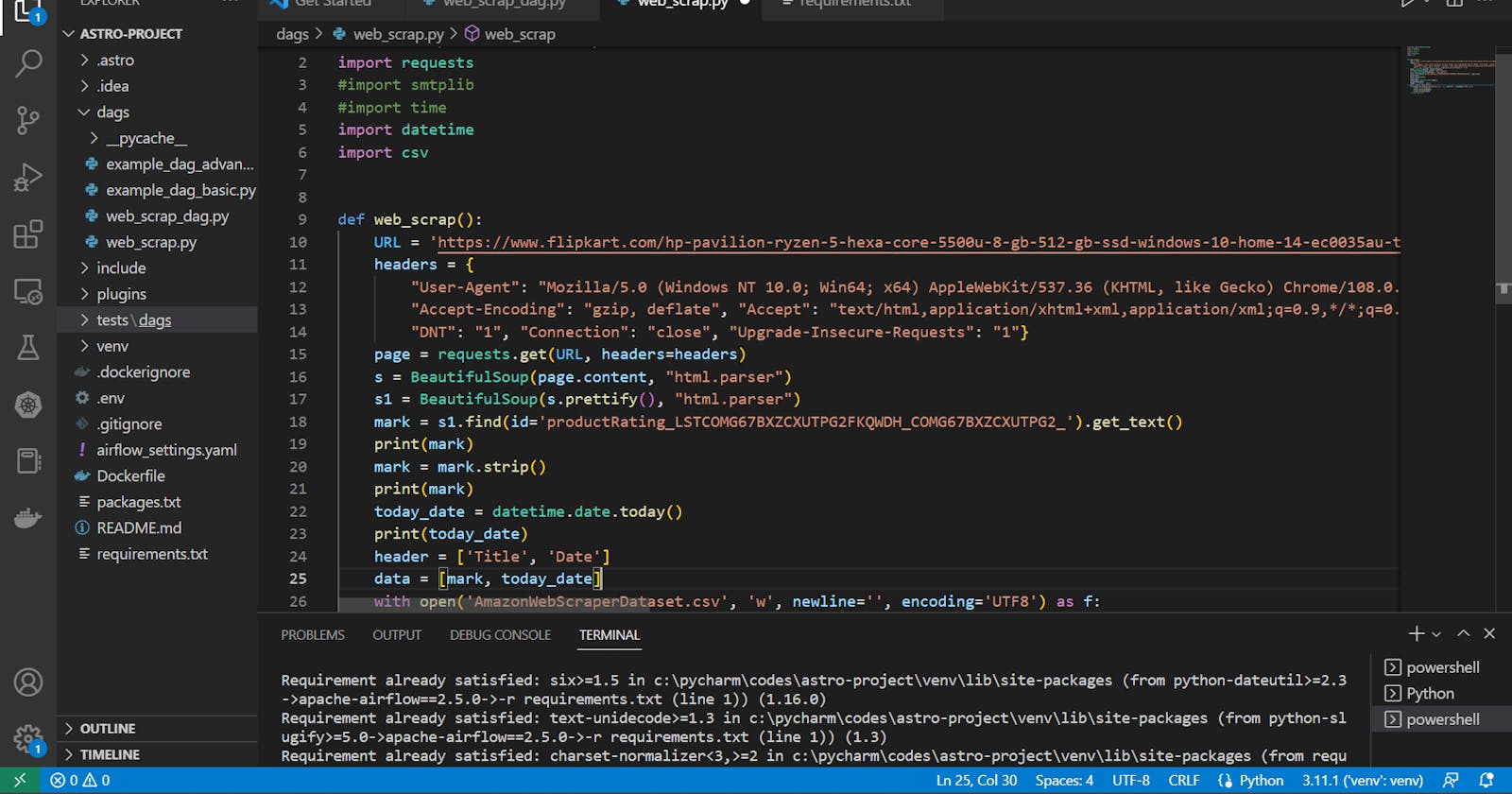
>>> from bs4 import BeautifulSoup
import requests
import datetime
import csv
>>> def myscrap():
URL = 'https://www.flipkart.com/hp-pavilion-ryzen-5-hexa-core-5500u-8-gb-512-gb-ssd-windows-10-home-14-ec0035au-thin-light-laptop/p/itmf7055ef4f789e?pid=COMG67BXZCXUTPG2&lid=LSTCOMG67BXZCXUTPG2FKQWDH&marketplace=FLIPKART&store=6bo%2Fb5g&srno=b_1_12&otracker=browse&fm=organic&iid=61ce0909-4573-4be0-8650-c12502df16e5.COMG67BXZCXUTPG2.SEARCH&ppt=None&ppn=None&ssid=9iuvjcdlm80000001671536456969'
# use 'https://httpbin.org/get' to get your User Agent
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36", "Accept-Encoding":"gzip, deflate", "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "DNT":"1","Connection":"close", "Upgrade-Insecure-Requests":"1"}
# requests is used to get the information about page from urls
page = requests.get(URL, headers=headers)
s = BeautifulSoup(page.content, "html.parser")
# after printing 's' you will get distorted data which isn't readable
# to make it more readable use prettify()
s1 = BeautifulSoup(s.prettify(), "html.parser")
mark= s1.find(id='productRating_LSTCOMG67BXZCXUTPG2FKQWDH_COMG67BXZCXUTPG2_').get_text()
# to make it more clear use strip()
mark= mark.strip()
# print(mark)
today_date = datetime.date.today()
#print(today_date)
# to write all data into a csv file
header = ['Mark', 'Today-date'] # column headers
data = [mark, today_date]
with open('flipkartwebscrappedfile.csv', 'w', newline='', encoding='UTF8') as f:
writer = csv.writer(f)
writer.writerow(header)
writer.writerow(data)